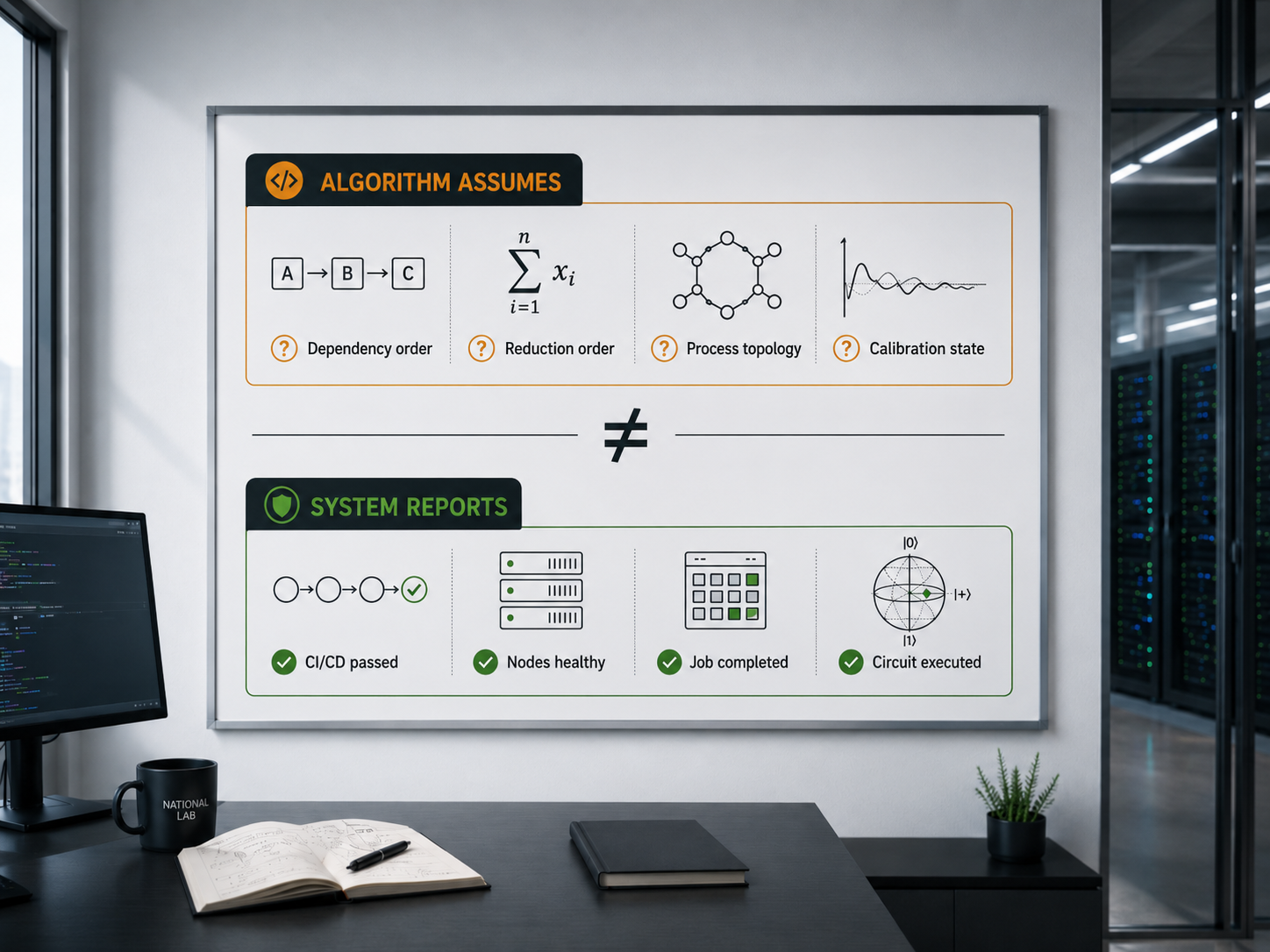
Why assumptions matter
Every piece of infrastructure we use to run scientific software was built by someone solving a different problem. CI/CD pipelines were designed to ship web applications reliably. HPC schedulers were designed to pack jobs efficiently onto shared hardware. Cloud orchestration platforms were designed to scale stateless services. Quantum job queues were designed to manage access to scarce physical hardware.
Most of these systems were not designed with the implicit assumptions of a scientific algorithm in mind. And scientific algorithms have a great many implicit assumptions. They assume that floating-point operations resolve in a consistent order across runs. They assume that data arrives with the dependencies resolved before the computation proceeds. They assume that the process topology established at job start remains stable through the final iteration. They assume that the hardware they are running on today matches the hardware the numerical method was tuned for.

The GPS app reports "Route ready" while hidden assumptions — map freshness, road closures, traffic, battery and signal — have already shifted; the success notification and the assumption layer operate on entirely separate planes.
The analogy maps directly onto the problem: the app is the system, the route plan encodes the hidden assumptions, and the trip result is the output — arriving at a plausible but wrong location is the scientific equivalent of a solver that converges to the wrong answer without raising an error.
The fix is not a smarter navigation layer alone; it requires making assumptions visible before the job starts, checking them live as the computation runs, and logging every environmental change that could alter the numerical outcome.
What makes this particularly difficult is that the failures are often not loud. A segfault is easy to find. A convergence that reached a wrong solution quietly, because floating-point reduction happened in a different order than the solver expected, is not. The system did exactly what it was asked to do. The algorithm's assumptions about what the system would do were never stated, never checked, and never honored.
The contract no one reads
Assumption mismatch occurs when the infrastructure satisfies its operational contract, but the algorithm's hidden scientific contract is violated. The system is not broken. The algorithm is not wrong. The gap between what the system guarantees and what the algorithm requires is simply never made visible, and that invisible gap is where silent failures live.[1]
Four Environments, Four Failure Modes
The mismatch between system success and algorithm correctness takes a different shape in each computational environment. In each case the failure is silent, plausible-looking, and only visible if you know what the algorithm was assuming in the first place.
Reading Failure as a Diagnostic Signal
The most underappreciated property of scientific algorithm failure is that it is structured. When a well-understood mathematical method breaks in a specific and reproducible way, the shape of the failure carries information about what the system actually did, information that no profiler or monitoring dashboard surfaces directly.
A distributed iterative solver that diverges when the number of MPI ranks changes is not telling you that the code is wrong. It is telling you that the convergence depends on a communication pattern that changes with the process count, and that dependency was never made explicit. A variational quantum algorithm whose result variance increases across repeated identical submissions is not telling you that quantum computing is unreliable. It is telling you that the device calibration state is drifting faster than the job queue is cycling submissions.
Standard system tools measure what happened at the resource layer. They tell you that CPU utilization was 94%, that network bandwidth was saturated, that memory allocation stayed within limits. What they cannot tell you is whether the sequence of operations the algorithm required was the sequence of operations the system actually produced. The algorithm, when it breaks in a way that is consistent with a specific violated assumption, tells you exactly that. The failure is a diagnostic. You have to be listening for it.
What This Means for Scientific Software Design
The practical consequence of assumption mismatch is that scientific software correctness cannot be delegated entirely to the infrastructure layer. The algorithm's assumptions need to be made explicit, documented, and where possible, verified at runtime rather than assumed at design time.
In practice this means a few specific things. Solvers that depend on process topology stability should detect and respond to topology changes rather than assuming they will not occur. Distributed algorithms that depend on reduction order should either enforce it explicitly or be validated against the numerical sensitivity to reordering. Quantum algorithms should record the device calibration state at submission and at execution and flag when they diverge beyond a threshold.[2]
None of this is about distrust of the infrastructure. CI/CD systems, HPC schedulers, cloud platforms, and quantum job queues are sophisticated and well-engineered. The point is not that they fail. The point is that they were designed to honor a different set of contracts than the ones scientific algorithms implicitly carry. Making those contracts visible is the scientist's responsibility, not the infrastructure's.[3]
Toward Assumption-Aware Scientific Pipelines
The path toward more reliable scientific computing at scale is not more powerful infrastructure alone. It is pipelines that understand what the algorithms running on them actually require, and that surface violations of those requirements as first-class signals rather than leaving them invisible beneath a layer of green checkmarks.
This requires closer collaboration between the people who design algorithms and the people who design the systems they run on. The algorithm designer knows what the computation requires. The systems engineer knows what the infrastructure can and cannot guarantee. The assumption mismatch that produces silent failures lives in the gap between those two bodies of knowledge. Closing that gap is one of the more important open problems in scientific computing infrastructure, and it becomes more pressing as the scale, heterogeneity, and dynamism of the systems we use continues to grow.
References
- [1] Stodden, V., McNutt, M., Bailey, D. H., Deelman, E., Gil, Y., Hanson, B., Heroux, M. A., Ioannidis, J. P. A., & Taufer, M. (2016). Enhancing Reproducibility for Computational Methods. Science, 354(6317), 1240 to 1241. Free copy: escholarship.org/uc/item/9wh3k06p. Cited for the framework that computational reproducibility requires explicit accounting of code, data, workflows, and the environment in which results were produced, not just re-running the final script.
- [2] Krantz, P., Kjaergaard, M., Yan, F., Orlando, T. P., Gustavsson, S., & Oliver, W. D. (2019). A Quantum Engineer's Guide to Superconducting Qubits. Applied Physics Reviews, 6(2), 021318. Free preprint: arxiv.org/abs/1904.06560. Cited for the treatment of qubit noise properties, coherence times, gate fidelity, and how superconducting qubit parameters drift over time, which underpins the calibration mismatch scenario described in the quantum section.
- [3] Wilson, G., Bryan, J., Cranston, K., Kitzes, J., Nederbragt, L., & Teal, T. K. (2017). Good Enough Practices in Scientific Computing. PLOS Computational Biology, 13(6), e1005510. Open access: doi.org/10.1371/journal.pcbi.1005510. Cited for the argument that making software dependencies, workflow decisions, and computational assumptions explicit is the responsibility of the scientist, not the infrastructure.
Written as a perspective on scientific software infrastructure and algorithm design. Jaya Preethi Mohan, University of North Dakota.